> ## Documentation Index
> Fetch the complete documentation index at: https://docs.starlight-search.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Introduction
> Python client for the Reflect learning API.
Most AI agents have no memory of what worked and what didn't. Every run starts from scratch - the same mistakes get made, the same dead ends get explored, and hard-won knowledge from previous tasks disappears the moment a session ends.
**Reflect gives your agents a long-term memory that gets smarter over time.**
When a task completes, Reflect records the full trajectory - every tool call, every decision, the final response, and whether the outcome was a success or failure. From that record it generates a concise reflection: what worked, what went wrong, and what to do differently next time. That reflection is stored as a memory with an initial utility score. Agents that already know the lesson can also author the reflection directly - via the MCP `create_memory` tool or the SDK - skipping the trajectory entirely.
The next time a similar task arrives, Reflect retrieves the most relevant memories and ranks them not just by semantic similarity, but by how useful they have proven in practice. Memories that consistently led to good outcomes rise to the top. Memories associated with failures are deprioritised until they are rehabilitated by a successful run.
Those ranked memories are injected into the agent's prompt before it runs - so the agent starts each task with the distilled experience of every previous run, not a blank slate.
## Works across workflows
Use Reflect with any agent that can call the API. It is not tied to a single model, framework, or agent runtime.
Plug Reflect into your existing setup, whether you run custom scripts, evaluators, agent loops, or lightweight MCP-based tooling.
Store and retrieve memories for debugging, implementation, documentation, testing, refactoring, and other kinds of work.
Memories created in one workflow can help with another. A reflection from a coding task can still be useful later in testing, docs, or review work when the task is relevant.
## The learning loop
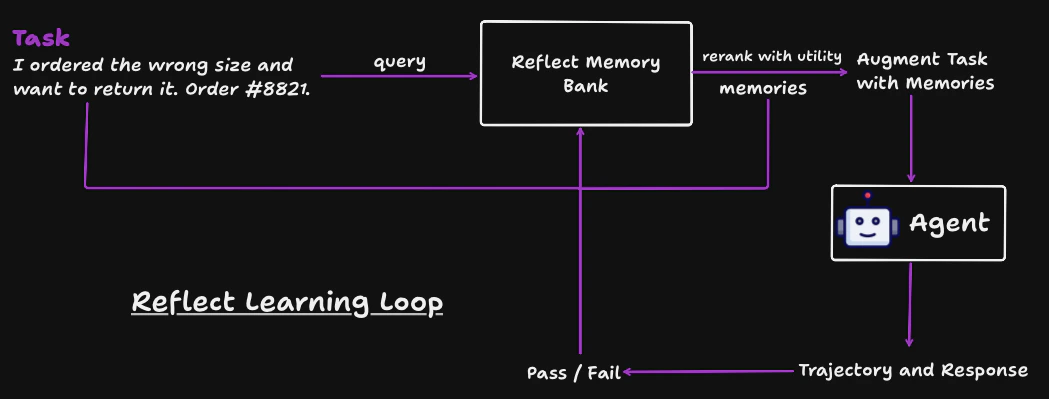 Before executing a task, retrieve relevant reflections from past runs. Memories are ranked by learned utility.
Append retrieved memories to the task text. The SDK formats successful and failed reflections into sections your LLM can use as context.
Your agent generates a response using the memory-augmented prompt.
Store the full trajectory - task, steps, final response, and which memories were used.
Mark the outcome as pass or fail. The API generates a new reflection memory and adjusts utility scores of the memories that were retrieved.
Future queries automatically favor reflections that led to success.
## Worked example
The following walks through a complete cycle. The agent is a customer support bot that handles refund requests.
### Step 1 - Query and rerank memories
A customer writes in: *"I ordered the wrong size and want to return it. Order #8821."*
Before the agent responds, Reflect fetches candidate memories from past support interactions and reranks them by blended score:
```
score = (1 - λ) × similarity + λ × q_value
```
With `λ = 0.5`, utility and semantic relevance contribute equally. A memory that consistently led to `pass` outcomes floats to the top even if it is not the closest semantic match.
| Memory | Similarity | utility | Score |
| ----------------------------------------------------------------- | :--------: | :-----: | :---: |
| Always confirm the order number exists before processing a return | 0.91 | 0.82 | 0.865 |
| Ask the customer to select a reason code before issuing a refund | 0.76 | 0.90 | 0.830 |
| Offer an exchange first - customers often prefer it over a refund | 0.88 | 0.74 | 0.810 |
Reranked order: \[1] confirm order \[2] ask reason code \[3] offer exchange
### Step 2 - Augment the task prompt
Reflect injects the top memories into the task before it reaches the agent:
```
Task (augmented):
Handle a return request for order #8821 - customer ordered the wrong size.
--- Reflect Memories ---
[PASS] Always look up the order number in the system before taking any action.
Proceeding without verifying led to refunds on non-existent orders.
[PASS] Ask the customer to confirm a return reason before issuing a refund.
Missing reason codes caused accounting reconciliation failures.
[PASS] Offer an exchange as the first option before escalating to a full refund.
Many customers prefer a replacement, which reduces refund costs.
--- End Memories ---
```
### Step 3 - Agent runs and produces a trajectory
The agent receives the augmented prompt, calls tools, and replies to the customer. A trajectory is the full record of that execution:
"I ordered the wrong size and want to return it. Order #8821."
Agent calls `lookup_order("8821")` to verify the order before taking any action.
**Result:** `{ item: "Running Shoes", size: "US 9", status: "delivered" }`
Agent calls `send_message` to contact the customer.
**Message sent:** "Hi Jamie - I can see order #8821 for Running Shoes (US 9). Would you prefer an exchange for a different size, or a full refund? Could you also confirm the reason for the return?"
**Result:** `{ status: "sent" }`
"I've verified your order and sent you an email to confirm your preference and return reason."
### Step 4a - Pass: reflection stored as a new memory
The agent verified the order, collected a reason, and offered an exchange first. The support team marks the outcome `pass`.
Reflect generates a reflection from the trajectory and stores it as a new memory:
```
[NEW MEMORY - q_value: 0.5 (initial)]
When handling a return or refund request:
1. Always look up the order in the system first before taking any action or
making promises - confirms the order is real and still eligible.
2. Ask the customer for a return reason before initiating anything -
required for accounting and policy compliance.
3. Offer an exchange before a refund - many customers accept it and it
reduces net refund volume.
4. Confirm the preferred resolution (exchange vs. refund) in the same
message to avoid an unnecessary back-and-forth round trip.
```
The utility scores of the three retrieved memories are updated upward (reward = 1.0):
```
q_new = q_old + α × (reward − q_old) where α = 0.1, reward = 1.0
mem_a1b2 "Always confirm the order number first" 0.82 → 0.838
mem_c3d4 "Ask for reason code before refund" 0.90 → 0.910
mem_e5f6 "Offer exchange before refund" 0.74 → 0.766
```
### Step 4b - Fail: reflection stored as a new memory
Now consider an earlier run, before these memories existed. The agent skipped the lookup and replied immediately:
> *"No problem! I've gone ahead and issued a full refund for order #8821. You'll see it in 3–5 business days."*
The order did not exist in the system - it had already been cancelled and refunded. The support team marks this `fail` with feedback: `"Refund issued on a cancelled order - no order lookup was performed"`.
Reflect generates a reflection from the failed trajectory and stores it as a new memory:
```
[NEW MEMORY - q_value: 0.5 (initial)]
## Incorrect assumptions
- Assumed the order number provided by the customer is valid without
verifying it in the system first.
- Assumed a refund was the right resolution without asking the customer
for their preference or a return reason.
## Steps to improve
- Always call lookup_order before taking any action on a return request.
- Collect the return reason and confirm the customer's preferred resolution
(exchange or refund) before proceeding.
## What to avoid next time
- Never issue a refund or exchange in the same turn as the initial request
without first verifying the order exists and is eligible.
- Avoid assuming a full refund is desired - an exchange is often preferred
and avoids unnecessary financial transactions.
```
The utility scores of any memories retrieved during that failed run are updated downward (reward = 0.0), so they surface less often until a successful run rehabilitates them.
***
Future support requests about returns will now retrieve these reflections, and the agent avoids the same mistakes automatically.
## Use cases by industry
Agents that write, review, or debug code learn which patterns led to passing tests and which caused regressions. A reflection from a failed code review surfaces automatically the next time a similar change is proposed.
Support agents learn from resolved tickets - what tone worked, which escalation paths succeeded, and which assumptions caused incorrect refunds or missed SLAs. Each outcome improves the next interaction.
Agents diagnosing equipment faults or generating maintenance plans retrieve memories from past incidents. A root-cause finding from a previous machine failure informs the response to a new one with similar symptoms.
Clinical decision-support agents retrieve prior case reflections when evaluating similar presentations. Memories from cases where a recommendation was later revised carry lower utility scores and are deprioritised automatically.
Contract review or compliance agents learn which clause interpretations were accepted by counsel and which were flagged. Accepted patterns are reinforced; rejected ones are down-ranked over time.
Agents generating investment summaries or risk assessments learn which analyses were signed off and which were sent back for revision. Approved reasoning patterns resurface on similar instruments.
## Next steps
Install the SDK with pip.
Create a client, query memories, and record a trace.
Query and augment tasks with past reflections.
Full ReflectClient method reference.
Before executing a task, retrieve relevant reflections from past runs. Memories are ranked by learned utility.
Append retrieved memories to the task text. The SDK formats successful and failed reflections into sections your LLM can use as context.
Your agent generates a response using the memory-augmented prompt.
Store the full trajectory - task, steps, final response, and which memories were used.
Mark the outcome as pass or fail. The API generates a new reflection memory and adjusts utility scores of the memories that were retrieved.
Future queries automatically favor reflections that led to success.
## Worked example
The following walks through a complete cycle. The agent is a customer support bot that handles refund requests.
### Step 1 - Query and rerank memories
A customer writes in: *"I ordered the wrong size and want to return it. Order #8821."*
Before the agent responds, Reflect fetches candidate memories from past support interactions and reranks them by blended score:
```
score = (1 - λ) × similarity + λ × q_value
```
With `λ = 0.5`, utility and semantic relevance contribute equally. A memory that consistently led to `pass` outcomes floats to the top even if it is not the closest semantic match.
| Memory | Similarity | utility | Score |
| ----------------------------------------------------------------- | :--------: | :-----: | :---: |
| Always confirm the order number exists before processing a return | 0.91 | 0.82 | 0.865 |
| Ask the customer to select a reason code before issuing a refund | 0.76 | 0.90 | 0.830 |
| Offer an exchange first - customers often prefer it over a refund | 0.88 | 0.74 | 0.810 |
Reranked order: \[1] confirm order \[2] ask reason code \[3] offer exchange
### Step 2 - Augment the task prompt
Reflect injects the top memories into the task before it reaches the agent:
```
Task (augmented):
Handle a return request for order #8821 - customer ordered the wrong size.
--- Reflect Memories ---
[PASS] Always look up the order number in the system before taking any action.
Proceeding without verifying led to refunds on non-existent orders.
[PASS] Ask the customer to confirm a return reason before issuing a refund.
Missing reason codes caused accounting reconciliation failures.
[PASS] Offer an exchange as the first option before escalating to a full refund.
Many customers prefer a replacement, which reduces refund costs.
--- End Memories ---
```
### Step 3 - Agent runs and produces a trajectory
The agent receives the augmented prompt, calls tools, and replies to the customer. A trajectory is the full record of that execution:
"I ordered the wrong size and want to return it. Order #8821."
Agent calls `lookup_order("8821")` to verify the order before taking any action.
**Result:** `{ item: "Running Shoes", size: "US 9", status: "delivered" }`
Agent calls `send_message` to contact the customer.
**Message sent:** "Hi Jamie - I can see order #8821 for Running Shoes (US 9). Would you prefer an exchange for a different size, or a full refund? Could you also confirm the reason for the return?"
**Result:** `{ status: "sent" }`
"I've verified your order and sent you an email to confirm your preference and return reason."
### Step 4a - Pass: reflection stored as a new memory
The agent verified the order, collected a reason, and offered an exchange first. The support team marks the outcome `pass`.
Reflect generates a reflection from the trajectory and stores it as a new memory:
```
[NEW MEMORY - q_value: 0.5 (initial)]
When handling a return or refund request:
1. Always look up the order in the system first before taking any action or
making promises - confirms the order is real and still eligible.
2. Ask the customer for a return reason before initiating anything -
required for accounting and policy compliance.
3. Offer an exchange before a refund - many customers accept it and it
reduces net refund volume.
4. Confirm the preferred resolution (exchange vs. refund) in the same
message to avoid an unnecessary back-and-forth round trip.
```
The utility scores of the three retrieved memories are updated upward (reward = 1.0):
```
q_new = q_old + α × (reward − q_old) where α = 0.1, reward = 1.0
mem_a1b2 "Always confirm the order number first" 0.82 → 0.838
mem_c3d4 "Ask for reason code before refund" 0.90 → 0.910
mem_e5f6 "Offer exchange before refund" 0.74 → 0.766
```
### Step 4b - Fail: reflection stored as a new memory
Now consider an earlier run, before these memories existed. The agent skipped the lookup and replied immediately:
> *"No problem! I've gone ahead and issued a full refund for order #8821. You'll see it in 3–5 business days."*
The order did not exist in the system - it had already been cancelled and refunded. The support team marks this `fail` with feedback: `"Refund issued on a cancelled order - no order lookup was performed"`.
Reflect generates a reflection from the failed trajectory and stores it as a new memory:
```
[NEW MEMORY - q_value: 0.5 (initial)]
## Incorrect assumptions
- Assumed the order number provided by the customer is valid without
verifying it in the system first.
- Assumed a refund was the right resolution without asking the customer
for their preference or a return reason.
## Steps to improve
- Always call lookup_order before taking any action on a return request.
- Collect the return reason and confirm the customer's preferred resolution
(exchange or refund) before proceeding.
## What to avoid next time
- Never issue a refund or exchange in the same turn as the initial request
without first verifying the order exists and is eligible.
- Avoid assuming a full refund is desired - an exchange is often preferred
and avoids unnecessary financial transactions.
```
The utility scores of any memories retrieved during that failed run are updated downward (reward = 0.0), so they surface less often until a successful run rehabilitates them.
***
Future support requests about returns will now retrieve these reflections, and the agent avoids the same mistakes automatically.
## Use cases by industry
Agents that write, review, or debug code learn which patterns led to passing tests and which caused regressions. A reflection from a failed code review surfaces automatically the next time a similar change is proposed.
Support agents learn from resolved tickets - what tone worked, which escalation paths succeeded, and which assumptions caused incorrect refunds or missed SLAs. Each outcome improves the next interaction.
Agents diagnosing equipment faults or generating maintenance plans retrieve memories from past incidents. A root-cause finding from a previous machine failure informs the response to a new one with similar symptoms.
Clinical decision-support agents retrieve prior case reflections when evaluating similar presentations. Memories from cases where a recommendation was later revised carry lower utility scores and are deprioritised automatically.
Contract review or compliance agents learn which clause interpretations were accepted by counsel and which were flagged. Accepted patterns are reinforced; rejected ones are down-ranked over time.
Agents generating investment summaries or risk assessments learn which analyses were signed off and which were sent back for revision. Approved reasoning patterns resurface on similar instruments.
## Next steps
Install the SDK with pip.
Create a client, query memories, and record a trace.
Query and augment tasks with past reflections.
Full ReflectClient method reference.